
Transformers are one in all many important trendy architectures utilized in each sequence modeling and pc imaginative and prescient. On the center of Transformers is the eye mechanism, which compares every ingredient of a sequence with each completely completely different ingredient. This pairwise
similarity rating is used to learn the way a lot the opposite tokens contribute to the mannequin new illustration of 1 ingredient. Whereas the technique provides state-of-the-art outcomes, it comes on the value of quadratic time complexity. Moreover, for language
interval, the next token prediction is linear inside the moment dimension, in contrast with
the mounted time complexity of approaches like Structured State Fashions (SSMs).
We introduce Latte, a mannequin new linear time and reminiscence substitute for normal consideration, which achieves a comparable effectivity to Transformers whereas being further environment nice all by means of instructing and inference. These properties are obligatory for doc
modeling or high-resolution seen query answering, the place enter might very properly be very extended. On this weblog put up, we deal with an intuitive clarification of Latte, nonetheless the technique is impressed and will very properly be merely understood from the lens of latent variables.
For a concise mathematical clarification, try our paper.
We’ll first rewrite the basic consideration mechanism contained in the non-vectorized selection, which is able to assist us describe the concept behind Latte.
As beforehand talked about, the bottleneck of irregular consideration is computing weights
 .
.
We mitigate this by introducing learnable latent tokens which could possibly be in contrast with every ingredient of the sequence. Because of the variety of latent tokens is mounted, the computation price turns into linear contained in the sequence dimension. Intuitively, we’re going to suppose
of the latent variables as ideas like colours or shapes to which we take into account the enter. Then our methodology creates a mannequin new illustration utilizing all of the sequence tokens and their similarity to the discovered high-level ideas. In Determine 2, we
present the excellence between bidirectional Latte and bidirectional customary consideration strategies.

The technique is analogous with sparse consideration strategies resembling BigBirdwhich solely compute consideration between a set of learnable worldwide tokens and
all of the sequence parts. Nonetheless, the principle distinction is that the sparse strategies are weighted sums of the worldwide tokens, whereas in our approach we think about your full sequence. Notably, we outline a particular parametrization of full
consideration utilizing latent variables, as a substitute of solely performing consideration between the latents and the sequence parts.
Defining our earlier assertion that focus has a probabilistic interpretation, we’re going to re-parameterize
with a weighted sum primarily based on
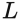 learnable latent variables:
learnable latent variables:

Contained in the above, we assumed independence between
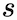 and
and
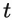 give
give
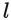 .
.
Intuitively, we compute the similarity between a high-level thought and every ingredient, then we re-weight it primarily based on the similarity between our present token and the high-level ideas. These ideas are our latent variables, which we
be taught end-to-end in duties like classification or language modeling. Subsequently, they might not primarily be interpretable. To calculate the chances above, we’re going to reuse the eye matrices
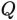 and
and
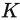 ,
,
giving us the mannequin new vector illustration of every token:

Uncover that
and
have utterly completely completely different sizes than the queries and keys throughout the typical consideration. Determine 3 describes intimately how we pay cash for these matrices.

Our formulation leads to
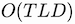 time and
time and
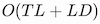 reminiscence complexity, in contrast with the
reminiscence complexity, in contrast with the
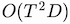 of the identical previous bidirectional approach. We outlined
of the identical previous bidirectional approach. We outlined
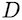 to be the vector dimension. The technique just isn’t completely new. Completely completely different works have decomposed consideration throughout the equal kind for the bidirectional case. Nonetheless, our probabilistic framework merely permits us to increase our mannequin to the causal
to be the vector dimension. The technique just isn’t completely new. Completely completely different works have decomposed consideration throughout the equal kind for the bidirectional case. Nonetheless, our probabilistic framework merely permits us to increase our mannequin to the causal
case.
Relative embeddings generalize larger to unseen sequence dimension compared with additive positional embeddings. Nonetheless, of their customary selection, they don’t make sense for use for latent tokens. We subsequently introduce VAPOR (worth embedded
positional rotations) which computes the relative distance between tokens, nonetheless with out affecting the eye weights:

Runtime Effectivity
We developed a way with linear time and reminiscence complexity contained in the sequence dimension. One draw again is that the causal model needs to be carried out sequentially to lower reminiscence utilization and have mounted time inference. If the sequence dimension
is small, this may be slower than a vectorized model of irregular consideration on GPUs. To see the advantages of Latte, we provide out an evaluation of runtime effectivity in Determine 4.

From the above, we’re going to see that the bidirectional case is quicker than the identical previous consideration even when the sequence dimension is small. Nonetheless, the sequential causal mannequin has the next runtime effectivity than causal consideration just for sequences longer
than 3,000 tokens. Within the case of reminiscence, Latte is further environment nice even when the sequence has a smaller dimension. The outcomes are counting on the variety of latent variables which give a tradeoff between runtime effectivity and the complexity
of a mannequin.
Extended Vary Area
Extended Vary Area is a man-made benchmark which checks the ability of fashions to seize long-range dependencies on sequences of two,000 to 16,000 tokens. The whole duties contained in the benchmark deal with the enter as a sequence of tokens
and are formulated as classification factors. Consequently, the effectivity of the mannequin is measured with accuracy, the place a larger rating means the next mannequin.
We implement the duties with a bidirectional Latte mannequin utilizing 40 latents and present that we outperform the identical previous consideration. The low variety of latents leads to a mannequin which is quicker than the identical previous consideration, whereas nonetheless having larger
effectivity. We furthermore take into account Bidirectional Latte to completely completely different environment nice Transformers and buy comparable outcomes, with the income that our methodology would possibly merely be utilized in each causal and bidirectional circumstances.

Language interval
For language modeling, we put collectively a Causal Latte mannequin on the next token prediction train. The datasets used are Wiki103, OpenWebText, and Enwik8. We tokenize the primary two with a byte pair encoding tokenizer, whereas for the latter we used a persona
tokenizer. The sequence lengths are 1,024 and some,048 for the 2 tokenization varieties. Two frequent metrics that we furthermore use to measure the success of this train are perplexity (PPL) and bits-per-character (BPC). PPL is the exponential of the
damaging log-likelihood, which implies {{{that a}}} decrease rating signifies the next mannequin. Equally, BPC is the damaging log-likelihood remodeled in primarily based two such that it signifies the variety of bits used to characterize a persona. As quickly as additional, a decrease
rating means the next mannequin.
We set the variety of latent variables
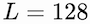 such that the mannequin is quicker than the identical previous causal consideration whereas shopping for comparable outcomes, as reported in Desk 2.
such that the mannequin is quicker than the identical previous causal consideration whereas shopping for comparable outcomes, as reported in Desk 2.

On token-level language modeling duties, Latte blended with VAPOR obtains scores near the identical previous consideration. That is confirmed by experiments on Wiki103 and OpenWebText datasets. We furthermore benchmark in course of Transformer-XL, a recursive mannequin
constructed for extended sequences, and we get larger outcomes for a comparable variety of parameters. Whereas these outcomes are promising contemplating the runtime choices, our mannequin has some disadvantages on character-level information objects like Enwik8. For
this setting, patterns are tougher to try and elementwise interplay between characters is susceptible to be required to extend effectivity. Nonetheless, the outcomes present a tradeoff between computational complexity and mannequin performance.
Impressed by the truth that language might very properly be decomposed into higher-level ideas, we developed a easy framework for bidirectional and causal circumstances that acts as another option to common consideration. Following the probabilistic interpretation,
our mannequin is straightforward to implement and has a quick and memory-effective runtime whereas it achieves larger or comparable effectivity on classification and language interval duties. One completely different good thing about our approach is that the next token prediction
runs in mounted time, leading to a quick mannequin all by means of interval. Latte is a versatile mannequin, which we might furthermore wish to make use of in multimodal duties like seen query answering. Affirm
out our code for extra particulars!